Transformer在AI领域曾独占鳌头,但随后暴露出计算量大、难以处理长序列等不足。近期,英伟达推出的Nemotron-H模型,为克服这些挑战提供了新的思路。
Transformer瓶颈凸显
近年来,Transformer在AI架构界独领风骚,应用范围广泛。不过,它的二次方复杂度问题使得计算资源消耗极大。特别是在处理长文本序列时,其表现明显不足,严重制约了大模型在推理阶段处理长文本的能力。这导致许多项目因计算能力和效率问题而进展缓慢。
Nemotron-H模型登场
NVIDIA最新推出的Nemotron-H系列,有两种型号,分别是8B和56B,其中精炼版更是高达47B。这个系列在技术层面实现了重大创新,将Transformer中的自注意力层替换为了Mamba - 2层。在Transformer和Mamba之间找到合适的平衡点,模型在处理长文本时效率提升,性能稳定,推理速度大幅提高,而且内存消耗也变得更加经济。
设计准则明确
研究者为使模型结构与标准Transformer模块相匹配,制定了三项设计准则。首先,模型的第一层必须使用Mamba-2架构,以便高效地进行初步处理。其次,最后一层需采用FFN层,以此来确保输出的稳定性。再者,自注意力层应置于FFN层之前,这有助于优化信息处理流程,同时保证模型结构的合理性与高效性。
预训练方法创新
在培养Nemotron - H模型的过程中,研究团队逐步实施了数据融合的办法。他们用8位浮点数进行训练。他们还确保模型起始和结束阶段的四个矩阵运算均以BF16的高精度进行,这样做是为了保证关键步骤的精确度。实验数据表明,使用FP8训练技术,在多个测试基准上均展现了出色的表现。这种方法不仅加快了训练进程,而且保证了模型的整体优质。
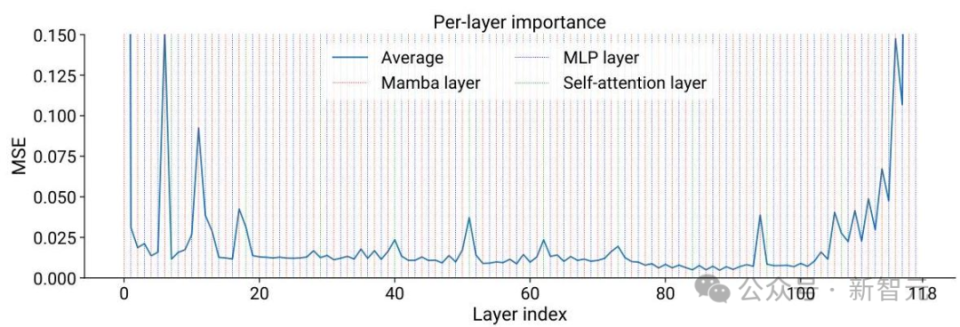
MiniPuzzle框架助力
MiniPuzzle框架详细介绍了从预训练到压缩模型的各个步骤。研究者要分析每一层的重要性,找出对模型性能影响大的层次。他们还需在内存消耗和性能之间找到平衡点,对模型进行评估,看其在内存占用和性能上是否均衡。
def importance_estimation(model, dataset):# Compute per-layer importance scores scores = []for layer in model.layers:# Zero out layer outputs and measure impact on loss scores.append(measure_impact_on_loss(model, layer, dataset))return scores
Mamba - 2优势显著
Mamba-2在性能上对Mamba进行了大幅增强。它的核心层状态转移矩阵结构得到了简化,同时增加了更大的头维度,从而使得训练效率提高了2至8倍。而且,它还采用了多头结构和张量并行等先进技术,进一步提升了模型的表达能力和并行计算效率。实验结果显示,Mamba-2在语言建模和多查询关联记忆任务上的表现超过了Mamba和基于注意力的模型。面对长序列,Mamba层的计算复杂度并未增加,从而大幅提升了处理效率。
大家对英伟达新出的产品有何见解?这款产品是否有望成为人工智能领域的新先锋?不妨在评论区留下你的看法。另外,别忘了给这篇文章点赞和转发。
